L’ASIC posa a la disposició de la comunitat investigadora un clúster de càlcul científic dedicat tant a treballs de procés distribuït com a treballs de memòria compartida, així com un sistema d’emmagatzematge d’alt rendiment, que proporciona a l’usuari un espai de disc unificat.
El nou clúster de càlcul científic consisteix en un supercomputador exaescala BullSequana XH3000, desenvolupat per la empresa Atos.
El sistema configurat en la UPV, i batejat amb el nom Sirius, consisteix en 33 nodes de còmput equipats amb processadors Intel Xeon 8480, de 56 cores, i 2 nodes accelerats amb 4 GPUs NVIDIA HGX H100, de 80GB. Ofereix una potència de càlcul sense precedents, aconseguint els 259Tflops per a propòsit general gràcies als seus 3696 cores de 2Ghz i 535Tflops de supercomputación en GPU e Intel·ligència Artificial.
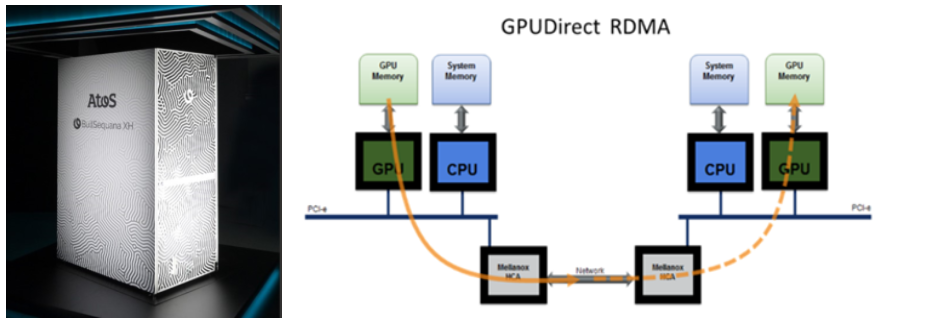
Els nodes accelerats estan interconnectats mitjançant 4 connexions NDR de 400Gb que donen un total de 1600Gb i GPU direct RDMA i P2P [ 1 ].
Ofereix a més connectivitat de xarxa de baixa latència mitjançant switches Infiniband NDR 400Gb, també refrigerats per DLC (Refigeración directa al Xip); espai d’emmagatzematge d’usuari (home directory) Isilon i nodes de login connectats a la xarxa general Ethernet de 2x25Gb i 10Gb.
Quant a l’emmagatzematge, el sistema Llustre SFA200NVX de Data Direct Network, empresa líder en el mercat ofereix 168TB bruts, i un mínim de 240TB gràcies als mecanismes de compressió. Els 22 discos d’estat sòlid són NVMe de generació 4 i 7.68TB per unitat.

El sistema de gestió del clúster HPC està basat en Bull Smart Management Center, sobre el Sistema Operatiu Linux Xarxa Hat 8 (edició HPC).
Aquest sistema permet la gestió centralitzada de tot el conjunt de servidors, per part del personal especialidado de l’ASIC, per a l’actualització del microprogramari, detecció i avís d’avaries, monitoratge del maquinari, instal·lació de programari, etc.
Del costat d’usuari final es disposa del programari de gestió de cues de procés Slurm i llibreries OpenMPI integrades amb la xarxa de baixa latència, així com les llibreries CUDA per a Nvidia i el sistema de contenidors Singularity.
A més es disposa de programari propietari del fabricador Intel One API, optimitzat el clúster descrit, amb compiladors C i Fortran, llibreries matemàtiques i entorns de programació, optimizadores de codi, etc.
A nivell intern, el personal de l’ASIC realitza un seguiment de l’estat de salut del clúster i d’ús de recursos monitorats per Prometheus i Grafana.
Es tracta probablement de el sistema de supercomputación amb millor PUE d’Espanya, amb 1.12, mitjançant refrigeració directa al xip (DLC) i free-cooling, i un de els més eficients de el món (Green500). És el segon sistema amb aquestes característiques, en el territori nacional, només per darrere del BSC Marenostrum.

La potència de càlcul de Sirius multiplica per cinc a el seu predecessor Rigel, gràcies principalment, a la incorporació de GPUs en el nou clúster.
[1] NVIDIA GPUDirect® és una família de tecnologies, part de Magnum IO, que millora el moviment i accés de dades per a les GPUs de centres de dades de NVIDIA. Utilitzant GPUDirect, els adaptadors de xarxa i les unitats d’emmagatzematge poden llegir i escriure directament des de/cap a la memòria de la GPU, eliminant còpies de memòria innecessàries, disminuint la sobrecàrrega de la CPU i reduint la latència, la qual cosa resulta en millores significatives del rendiment. Aquestes tecnologies – incloent GPUDirect Storage, GPUDirect remalnom Direct Memory Access (RDMA), GPUDirect Peer to Peer (P2P) i GPUDirect Vídeo – es presenten a través d’un conjunt complet d’APIs.
Condicions d’ús del servei de Càlcul Científic
- El Servei de Calculo Cientifico es presta únicament amb finalitat acadèmica o d’investigació, sense estar permesos altres usos.
- Els arxius que ja no siguen necessaris per a prosseguir els treballs de recerca han de ser eliminats del sistema per a alliberar espai d’emmagatzematge. Això és sense perjudici que puguen addicionalment ser sotmesos a límits o a neteges automàtiques.
- Els usuaris col·laboraran en la mesura de les seues possibilitats al funcionament eficient del sistema. En particular, els treballs de càlcul no requeriran més recursos dels estrictament necessaris.
- Quan els resultats de treballs executats en el clúster s’incorporen a qualsevol publicació, s’haurà d’esmentar en aquesta que s’ha utilitzat el clúster Rigel de la UPV per a obtenir els resultats. Així mateix, l’Àrea de Sistemes d’Informació i Comunicacions (ASIC), com a gestora del clúster Rigel, podrà recaptar als investigadors informació sobre la producció científica facilitada per l’ús del clúster.
- També són aplicable les normes i condicions relacionades en el Reglament de seguretat de recursos informàtics de la Universitat Politècnica de València.
Com sol·licitar un compte
- El clúster està destinat exclusivament a la investigació.
- Els responsables dels grups d’investigació, centres, o departaments interessats a llançar el seu treballs de cues al clúster hauran de sol·licitar-lo via Gregal.
- Una vegada acceptada la sol·licitud per part de l’ASIC, els responsables podran gestionar els usuaris finals des del seu Intranet , i aquests al seu torn hauran d’acceptar les condicions d’ús particulars també via Intranet.
- El clúster està subjecte al compliment de el Reglament de seguretat de recursos informàtics de la Universitat Politècnica de València.
Ús del clúster Sirius
Entorn de treball
- Tots els nodes del sistema Sirius tenen instal·lada la mateixa versió de Sistema Operatiu, RedHat HPC Edition 8, i la mateixa configuració, tant del sistema operatiu com llibreries i utilitats.
- El gestor de cues és Slurm, i tot treball ha de ser enviat a través de cues per a la seua execució. Quan un usuari es dona d’alta en Sirius, se li indicarà la manera d’enviar els seus treballs a través de manuals i documentació en línia.
- Les opcions especificades en l’envio de treballs permeten al sistema Sirius assignar a les diferents cues els treballs segons requeriments especificats.
- L’esquema d’autenticació és per LDAP i la contrasenya es valguda amb Active Directory de la UPV.
- Els usuaris no poden accedir de manera interactiva als nodes de càlcul, només treballen en els nodes de capçalera, als quals poden accedir per ssh. El frontend d’usuari és un clúster en alta disponibilitat de dos sistemes, i la seua adreça és sirius.upv.es
- El directori home de l’usuari està muntat en /home/grup/usuari en tots els nodes de tots els clústers.
Sistema de cues
- Perquè l’ús del sistema siga el mes efectiu possible, tots els treballs de càlcul han d’enviar-se sempre per mitjà del gestor de cues.
- El gestor de cues li assignara recursos quan li arribe el seu torn.
- El gestor de cues instal·lat en en Sirius és Slurm.
- Existeix una sèrie de manuals, guies d’inici ràpid, etc, en el lloc oficial de Slurm a la disposició dels usuaris la lectura dels quals recomanem.
Notes d’interès
- Les cues definides en aquest moment limiten el temps d’ejecucion d’un treball a un maximo de 144 hores i el temps total de cpu (numere de processadors * temps d’ejecucion ) a un maximo de 1000 hores. Aquests paràmetres es poden anar modificant per a optimitzar el rendiment del sistema.